Now that the tennis season is well underway and the Australian Open is already a few weeks in the past, I thought I would look at a basic model of a game of tennis for today’s blog post. As you might expect there will be some maths later on, but feel free to skip that and just look at the pictures and the results!
The simplest way to model a tennis match as suggested by people such as O’Malley, is to look at the probability of players winning a point on their own serve. Then we can define the probability of a player winning a point on their serve as p, and the probability of losing a point on their serve as 1-p. These two probabilities can be used to build up a model of the entire match. Whilst this is clearly a simplification it has been shown to be a pretty good predictor of the overall winner of a match.
For example by checking the ATP website we can see that Roger Federer won 3737 out of 5202pts he played on serve last year, giving him an average probability of p=0.718 to win a point on his serve. Giles Simon only managed to win 3186 out of 5128pts on his serve and consequently had a more typical value of probability p=0.621 to win a game on his serve. Most top-50 ATP players had values in the range of 0.6 to 0.7 for the 2015 season, which is obviously pretty good!




 (the true distribution) that match the properties of the real world data
(the true distribution) that match the properties of the real world data 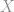 .
.![\mu_{X} = E[X]](https://s0.wp.com/latex.php?latex=%5Cmu_%7BX%7D+%3D+E%5BX%5D&bg=ffffff&fg=808080&s=0&c=20201002)
![\sigma^2_{X} = E[(X-\mu_{X})^2]](https://s0.wp.com/latex.php?latex=%5Csigma%5E2_%7BX%7D+%3D+E%5B%28X-%5Cmu_%7BX%7D%29%5E2%5D+&bg=ffffff&fg=808080&s=0&c=20201002)
![\alpha_{3} = E[(X-\mu_{X})^3]/\sigma^3_{X}](https://s0.wp.com/latex.php?latex=%5Calpha_%7B3%7D+%3D+E%5B%28X-%5Cmu_%7BX%7D%29%5E3%5D%2F%5Csigma%5E3_%7BX%7D+&bg=ffffff&fg=808080&s=0&c=20201002)
![\alpha_{4} = E[(X-\mu_{X})^4]/\sigma^4_{X}](https://s0.wp.com/latex.php?latex=%5Calpha_%7B4%7D+%3D+E%5B%28X-%5Cmu_%7BX%7D%29%5E4%5D%2F%5Csigma%5E4_%7BX%7D+&bg=ffffff&fg=808080&s=0&c=20201002)
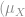 ,
,  ,
,  and they all exist. Then there is a fairly standard trick that lets us match the mean and variance easily,
and they all exist. Then there is a fairly standard trick that lets us match the mean and variance easily,
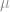 and variance
and variance 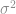 , but the same skewness and kurtosis as X. As a result it is not the matching of the first two central moments that poses a problem, but the matching of the next two!
, but the same skewness and kurtosis as X. As a result it is not the matching of the first two central moments that poses a problem, but the matching of the next two!
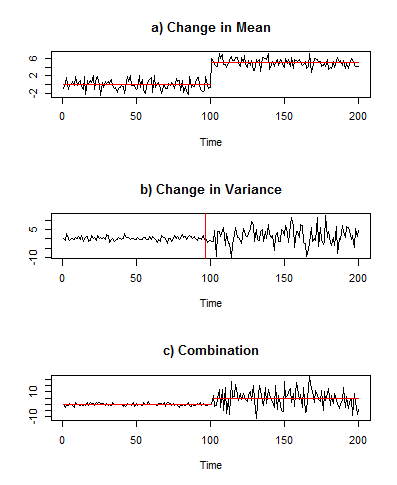
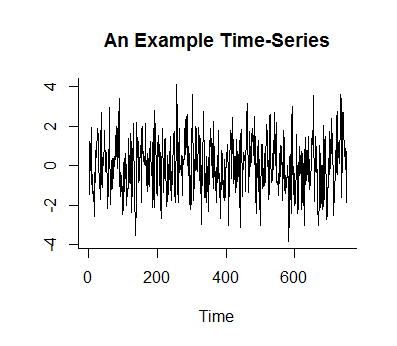 When we look at time-series data we often see sudden changes in the pattern of the data. We use the term ‘changepoints’ to describe the places where this occurs. In a more mathematical sense changepoints tend to happen when there is some change in the parameters of the data, i.e in the mean or variance of the series. Sometimes changepoints even occur when more than one parameter of the data changes.
When we look at time-series data we often see sudden changes in the pattern of the data. We use the term ‘changepoints’ to describe the places where this occurs. In a more mathematical sense changepoints tend to happen when there is some change in the parameters of the data, i.e in the mean or variance of the series. Sometimes changepoints even occur when more than one parameter of the data changes.