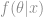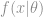There are two main strands of statistics, Classical statistics and Bayesian statistics. These aren’t necessarily conflicting ideologies, though many statisticians throughout history would beg to differ, but are simply two different ways to tackle a problem. Hopefully this post will give you some brief insight into the uses and differences of the two approaches.
Classical statistics is the first type of statistics that people come across and is to do with what we expect to happen in a repeatable experiment. This might be the idea that if we flip a coin an infinite number of times the proportion of heads we obtain is a half. Hence we get the well known probability of a head as a 1/2. This is why classical statistics is often known as frequentist and covers ideas such as confidence intervals and p-values.
Bayesian statistics evolved out of Bayes’ Theorem which I talked about in a previous post.
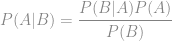
- P(A), P(B) are known as prior probabilities, because we know them before we learn any more information.
- P(A|C), P(B|C) are known as posterior probabilities, because they are found after we have learnt some additional information.
You can think of this Bayesian statistics as an evolution of Bayes’ Theorem. Instead of dealing with point probabilities we now deal with probability distributions. As a result we now have prior and posterior distributions to consider.
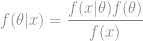
As the term 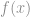

Here